


Architecting the Data Platform
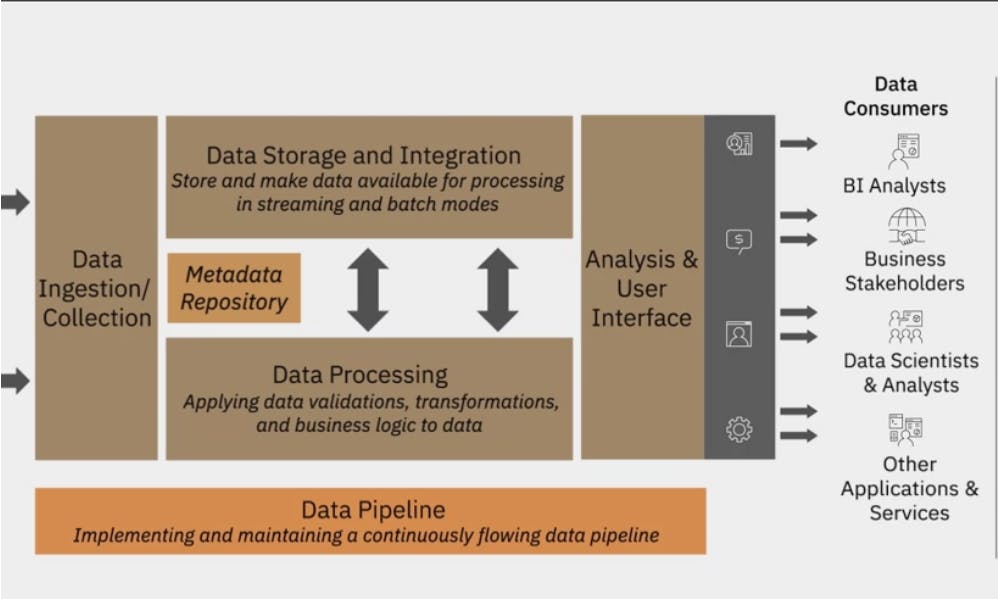
Layers of a data platform architecture, A layer represents functional components that perform a specific set of tasks in the data
- Data Ingestion or Data Collection layer
- Data Storage and Integration Layer
- Data Processing layer
- Analysis and user Interface Layer
- Data pipeline Layer
Data Ingestion or Data Collection layer:
- Connect to data stores
- Transfer data from data stores to the data platforms in streaming and batch modes.
- Maintain information about the data collected in the metadata repository.
- Tools: Google DataFlow, IBM Streams, IBM Streaming Analytics on the cloud, Amazon Kinesis, and Kafka. Data Storage and Integration Layer:
- Store data processing and long term
- Transform and merge extracted data, either logically or physically
- Make data available for processing in both batch and stream modes.
- Tools: IBM DB2, Microsoft SQL Server, MySQL, Oracle DB, PostgreSQL
- Cloud DB is referred to as Database as a Service, tools available in this are IBM DB2, Amazon RDS, Google Cloud SQL, and SQL Azure. In the non-relational DB on the cloud we have: Cassandra, Neo4j, Cloudant IBM, Redis, and MongoDB.
- Tools for integration include IBM's cloud Pak for data, IBM's cloud oak for integration, Talend data fabric, and OpenStudio.
- Open source Integration tools: Boomi and SnapLogic
Data Processing:
- Read data into batch or streaming modes from storage and apply transformations
- Support popular querying tools and programming languages
- Scale to meet the processing demands of a growing dataset
- Provide a way for analysts and data scientists to work with data in the data platform. Transformation Tasks :
- Structuring: Actions that change the form and schema or data.
- Normalization: Cleaning the database of unused data and reducing redundancy and inconsistency.
- Denormalization: Combining data from multiple tables into a single table that can be queried more efficiently.
- Data Cleaning: Fixing irregularities in data to provide credible data for downstream applications and uses.
- Storage and processing may not always be performed in separate layers.
- In RDBMS: Storage and processing can occur in the same layer
- In big Data Systems: Data can be first stored in HDFS, and then processed in a data processing engine like a spark.
- Data processing layer can also precede the data storage layer, where transformations are applied before the data is loaded or stored in the database.
There is a host of tools available for performing these transformations on data, selected based on the data size, structure, and specific capabilities of the tool. some of these tools are : Spreadsheets, OpenRefine, Google DataPrep, Watson Studio Refinery, and Trifacta Wrangler.
Analysis and user Interface Layer:
- Delivers processed data to data consumers such as BI Analysts, Business Stakeholders, dATA scientists and Analysts, and other applications and services.
- Querying tools and programming languages SQL, SQL-Like query tools for NoSQL, programming languages like python, R, and Java
- API's that can be used to run reports on data for both online and offline processing
- APIs that can consume data from the storage in real-time for use in other applications and services.
Data pipeline Layer:
- Overlaying the Data Ingestion, data storage, and Integration, and data processing layers is the data pipeline layer with the Extract, Transform and Load tools.
- This layer is responsible for implementing and maintaining a continuously flowing data pipeline.
- Data pipeline solutions: Apache Airflow and DataFlow.
Factors for Selecting and Designing Data Stores A data store or repository is a general term used to refer to data that has been collected, Organized, and isolated to be used for business operations or mined for reporting and data analysis
A repository can be:
- database
- Data warehouse
- Data Mart
- Data Lake
- Big Data Store
Primary considerations for designing a data store:
- Type of data
- Volume of data
- Intended use of data
- Storage Considerations
- Privacy, security, and Governance Needs Type of Data : There are multiple types of databases and selecting the right one is a crucial part of designing. input, storage, search and retrieval, and modification.
- Types are Relational and non Relational
- Relational (RDBMS) is best for structured data which is a well-defined schema that can be organized in a tabular format.
- Non-Relational: Best used for semi-structured and Unstructured data, data that is schema-less and free form. 4 types in NoSQL Db: Key value, Document based, Column based, and Graph based.
Data Lake:
- Store large volumes of raw data in its native format, straight from its source
- Store both relational and non-relational data at scale without defining the data's structure and schema.
Big-data Store:
- Store data that is high-volume, high velocity, of diverse types, needs distributed processing for fast analytics.
- Big Data Stores split large files across multiple computers allowing parallel access to them.
- Computations run in parallel on each node where data is stored. Intended use of data How you intend to use the data you are collecting :
- Number of Transactions
- Frequency of updates
- Types of Operations
- Response Time
- Backup and Recovery
The intended use of data also drives scalability as a design consideration. The scalability of a data store is its capability to handle growth in the amount of data, workloads, and users. Normalization is another important consideration at the design stage, it helps.
- Optimal use of storage space
- Makes database maintenance easier
- Provides fasters access to data.
- Normalization is important for systems that handle transactional data but for systems designed for handling analytical queries, normalization can lead to performance issues.
Storage Considerations: Design considerations from the perspective of storage: Performance, Availability, Integrity, and Recoverability of Data. A secured data strategy is a layered approach, it includes : Access Control, Multizone Encryption, Data management, and monitoring systems.
- Regulations such as GDFP, CCPA, and HIPAA restrict the ownership, use, and management of personal and sensitive data. Data needs to be made available through controlled data flow and data management by using multiple data protection techniques.
- This is an important part of a data store design. Strategies for data privacy, security, and government regulations need to be an of a data store's design from the start. Done at a later stage it results in patchwork.
SUMMARY
The architecture of a data platform can be seen as a set of layers, or functional components, each one performing a set of specific tasks. These layers include:
- Data Ingestion or Data Collection Layer, responsible for bringing data from source systems into the data platform.
- Data Storage and Integration Layer, responsible for storing and merging extracted data.
- Data Processing Layer, responsible for validating, transforming, and applying business rules to data.
- Analysis and User Interface Layer, responsible for delivering processed data to data consumers.
- Data Pipeline Layer, responsible for implementing and maintaining a continuously flowing data pipeline.
A well-designed data repository is essential for building a system that is scalable and capable of performing during high workloads.
The choice or design of a data store is influenced by the type and volume of data that needs to be stored, the intended use of data, and storage considerations. The privacy, security, and governance needs of your organization also influence this choice.
The CIA, or Confidentiality, Integrity, and Availability triad are three key components of an effective strategy for information security. The CIA triad is applicable to all facets of security, be it infrastructure, network, application, or data security.