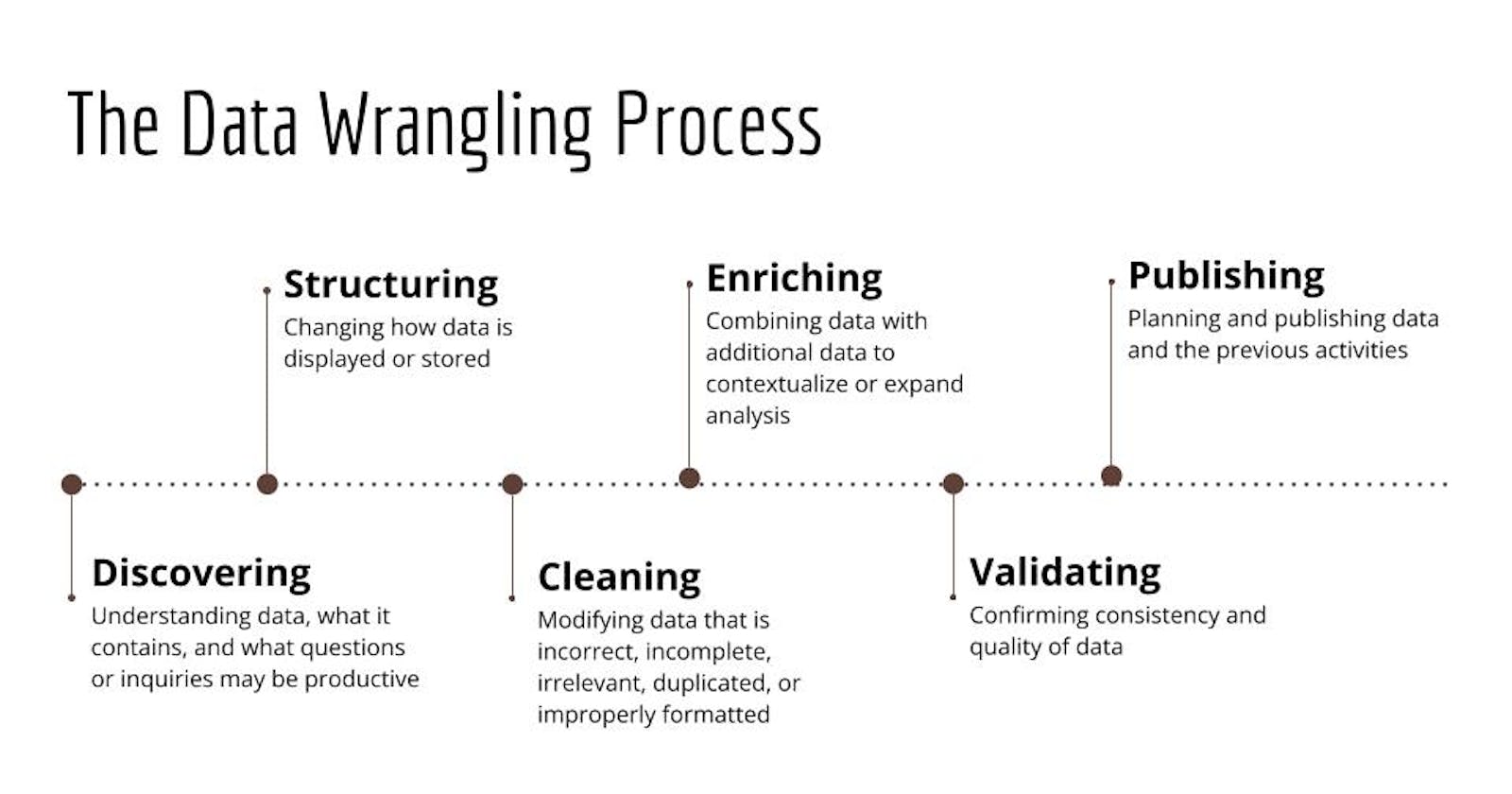


Data wrangling or Data Munging is a process that involves:
- data Exploration
- Transformation
- Validation
- Making Data available for credible and meaningful analysis
Structuring data:
- The task includes actions that change the form and schema of your data.
- The incoming data can be in varied formats.
- You might, for example, have some data coming from a relational database and some data from Web APIs. In order to merge them, you will need to change the form or schema of your data. This change may be as simple as changing the order of fields within a record or dataset or as complex as combining fields into complex structures.
- Normalization focuses on cleaning the database of unused data and reducing redundancy and inconsistency. Data coming from transactional systems, for example, where a number of inserts, update, and delete operations are performed on an ongoing basis, are highly normalized.
- Denormalization is used to combine data from multiple tables into a single table so that it can be queried faster.
- For example, normalized data coming from transactional systems is typically denormalized before running queries for reporting and analysis. Another transformation type is Cleaning. Cleaning tasks are actions that fix irregularities in data in order to produce a credible and accurate analysis.
Inspection :
- Detecting issues and errors
- Validating against rules and constraints
- Profiling data to inspect source data
- Visualizing data using statistical methods
Missing values:
- Can cause unexpected or biased results
- Filter out records with missing data
- Source missing information
- Imputate, that is, calculate the missing value based on statistical values.
Duplicate data and Cleaning:
- points that are repeated in your dataset
- Irrelevant data is data that is not contextual to your use case.
- Data type conversion is needed to ensure that values in fields are stored as the data type of that field
- Standardizing data is needed to ensure date-time formats and units of measurement are standard across the dataset.
- Syntax errors such as white spaces, extra spaces, types, and formats need to be fixed.
- Outliers need to be examined for accuracy and inclusion in the dataset.
Tools for data wrangling:
- Excel Power Query/ Spreadsheets: such as Microsoft Excel and Google sheets have a host of features and n-built functions to identify issues, and clean and transform data. Microsoft Power Query for excel and google sheets query function for google sheets are add-ins that allow importing data from different sources and cleaning and transforming data as needed.
- OpenRefine: Open source tool, that imports, and export data in a wide variety of formats such as TSV, CSV, XLS, XML, and JSON. easy to learn and use. Can clean, transform it from one format to another, and extend data with web services and external data.
- Google DataPrep: Can visually explore, clean, and prepare both strut and un struct data for analysis, fully managed service, Extremely easy to use, offers suggestions on ideal next steps, automatically detects schemas, datatypes, and anomalies.
- Watson Studio Refinery: Discover, clean and transform data with in-built operations. Transform large amounts of raw data into consumable quality information ready for analytics. The flexibility of exploring data residing in a spectrum of data sources. Detects data types and classifications automatically. enforces data governance policies automatically.
- Trifacta Wrangler: Interactive cloud-based service for cleaning and transforming data, takes messy, real-world data and cleans and arranges it into data tables. export tables to Excel, Tableau, and R, known for collaboration features.
Querying and Analyzing data
- Counting and Aggregating
- Identifying extreme values
- Slicing and sorting data
- Filtering patterns
- Grouping data
- Cassandra CQL( for non-relational DB)
- Cypher for Neo4J ( SQLike for NoSQL db)