


ETL has historically been used for batch workloads on a large scale. They're being used for real-time streaming as well. popular ETL tools: IBM Infosphere information server, AWS Glue, Improvado, Skyvia, Hevo, Informatica.
ETL ( Extract Load Transform):
- Gathering raw data
- Extracting information needed for reporting and analysis
- Cleaning, standardizing, and transforming data into a usable format.
- Loading data into a data repository.
Extraction can be through:
- Batch Processing: Large chunks of data are moved from source to destination at scheduled intervals. example: Blend, Stitch.
- Stream Processing: Data pulled in real-time from the course, transformed in transit, and loaded into the data repository. example: Samza, Storm
Transformation:
- Standardizing data formats and units of measurement.
- Removing duplicate data
- Filtering out data that is not required
- Establishing key relationships across tables
Loading:
- Loading is the transportation of processed data into a data repository.
- Initial Loading: Populating all of the data in the repository.
- Incremental Loading: Applying updates and modifications periodically.
- Full refresh: Erasing a data table and reloading fresh data.
Load Verification includes checks for:
- Missing or Null values
- Server performance
- Load Failures.
ELT ( Extract, Load, Transform)
- Helps process large sets of unstructured and non-relational data
- Is ideal for data lakes Advantages :
- Since raw data is delivered directly to the destination without the staging environment as ETL shortens the cycle between extraction and delivery.
- Allows you to ingest volumes of raw data as immediately as the data becomes available.
- Affords greater flexibility to analysts and data scientists for exploratory data analytics.
- Transforms only that data that is required for a particular analysis so it can be leveraged for multiple use cases.
- More suited to work with big data.
Data Pipelines
- Encompasses the entire journey of moving data from one system to another, including the ETL process.
- Can be used for both batch and streaming data
- Supports both long-running batch queries and smaller interactive queries.
- Typically loads data into a data lake but can also data into a variety of target destinations - including other applications and visualization tools.
- Example: Beam, Airflow, and DataFlow
Data Integration how does data integration relate to ETL and Data Pipelines?
While data integration combines disparate data into a unified view of the data, a data pipeline covers the entire data movement journey from source to destination systems. In that sense, you use a data pipeline to perform data integration, while ETL is a process within data integration. There is no one approach to data integration.
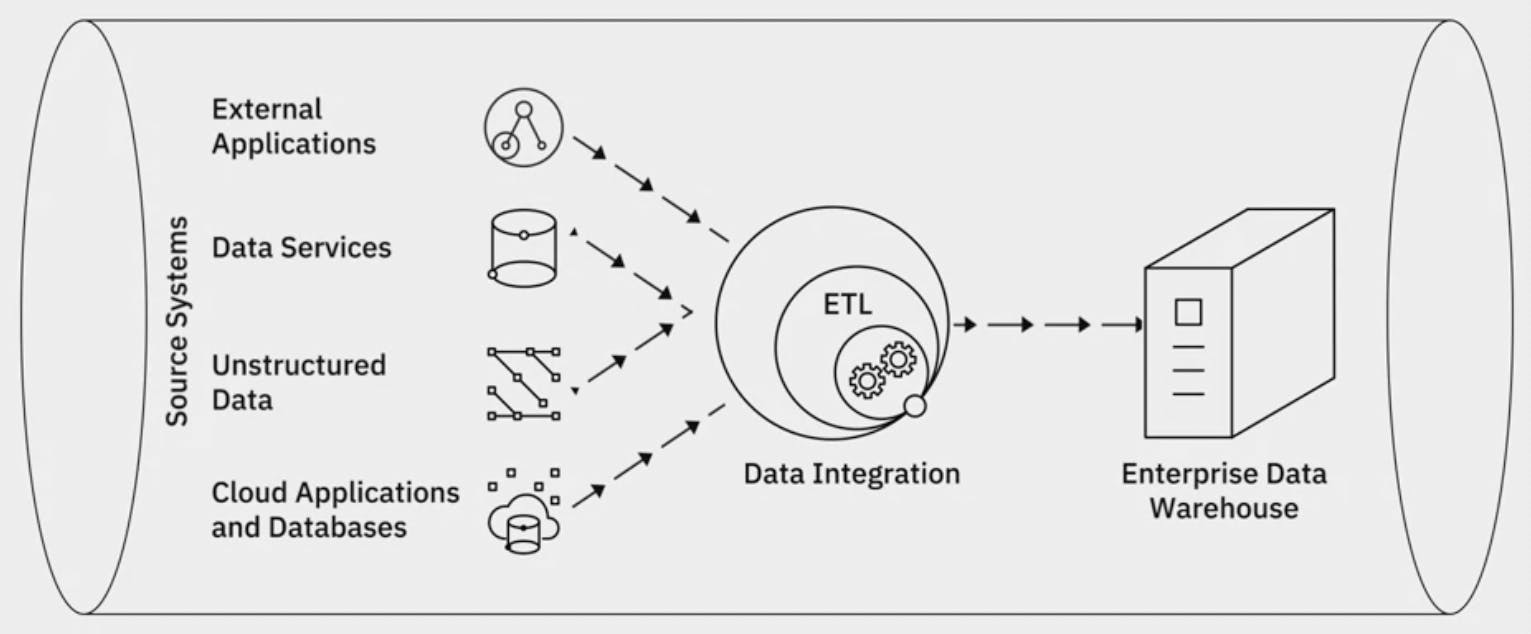
Capabilities of modern integration platform:
- Pre-built connectors and adapters.
- Open-source architecture
- Optimization for both batch processing of large-scale data and continuous data streams or both.
- Integration with big data sources.
- additional functionalities for data quality and governance, compliance, and security.
- Portability between on-premise and different types of cloud environments.
Data Integration Tools: IBM Offers:
- IBM Information Server
- cloud Pak for Data
- Cloud Pak for Integration
- Data Replication
- Data Virtualization
- InfoSphere Information Server on Cloud
- IBM InforSphere DataStage Talend Offers:
- Talend Data Fabric
- Talend Cloud
- Talend Data Catalog
- Talend Data Management
- Talend Big Data
- Talend Data Services
- Talend Open Studio others :
- SAP
- Oracle
- Dendo
- SAS
- Microsoft
- QlikQ
- Tibco Cloud-based Integration Platform as a Service ( iPaaS):
- Adaptia Integration Suit
- Google Cloud Cooperation 534
- IBM Application Integration Suit on cloud
- Informatica's Integration cloud.
SUMMARY A Data Repository is a general term that refers to data that has been collected, organized, and isolated so that it can be used for reporting, analytics, and also for archival purposes.
The different types of Data Repositories include:
- Databases, which can be relational or non-relational, each following a set of organizational principles, the types of data they can store, and the tools that can be used to query, organize, and retrieve data.
- Data Warehouses, that consolidate incoming data into one comprehensive storehouse.
- Data Marts, which are essentially sub-sections of a data warehouse, are built to isolate data for a particular business function or use case.
- Data Lakes, serve as storage repositories for large amounts of structured, semi-structured, and unstructured data in their native format.
- Big Data Stores, provide distributed computational and storage infrastructure to store, scale, and process very large data sets.
The ETL, or Extract Transform and Load, Process is an automated process that converts raw data into analysis-ready data by:
- Extracting data from source locations.
- Transforming raw data by cleaning, enriching, standardizing, and validating it.
- Loading the processed data into a destination system or data repository.
The ELT, or Extract Load and Transfer, Process is a variation of the ETL Process. In this process, extracted data is loaded into the target system before the transformations are applied. This process is ideal for Data Lakes and working with Big Data.
Data Pipeline, sometimes used interchangeably with ETL and ELT, encompasses the entire journey of moving data from its source to a destination data lake or application, using the ETL or ELT process.
Data Integration Platforms combine disparate sources of data, physically or logically, to provide a unified view of the data for analytics purposes.